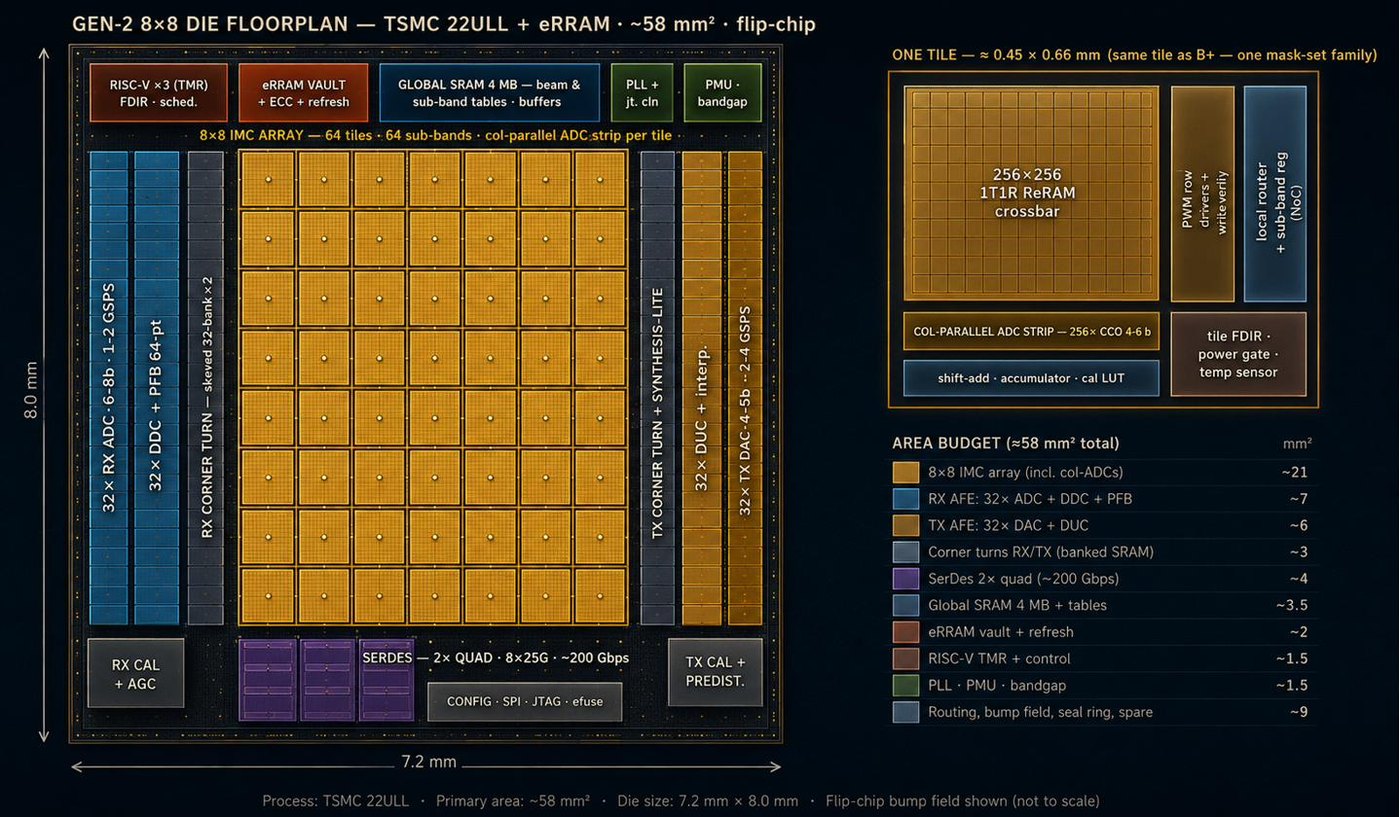
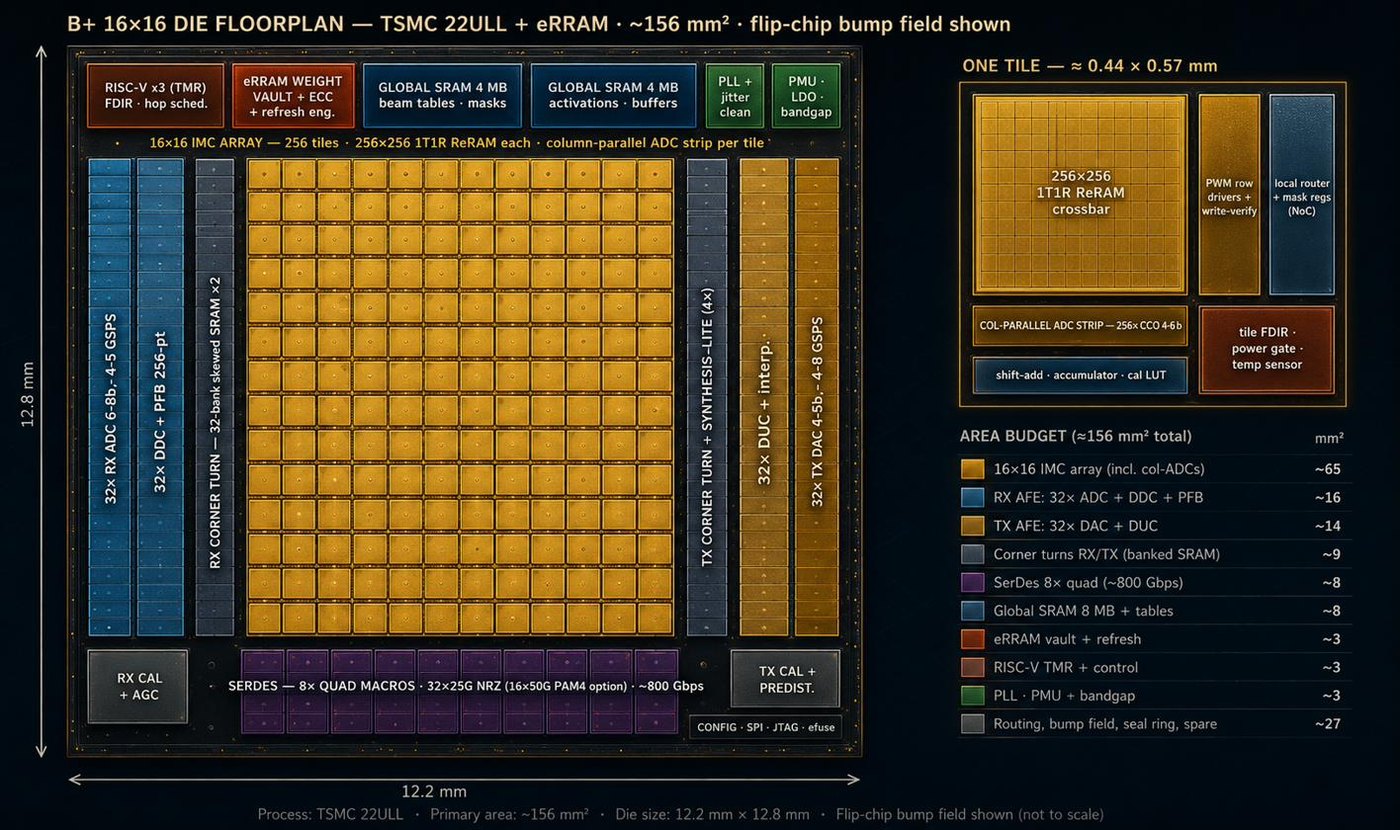
The principle
Three laws of physics, one operation.
The weights of a neural network are stored as the electrical conductance of nanoscale ReRAM cells. From there, the arithmetic is just what the devices already do.
OHM'S LAW
The cell multiplies
Drive a cell of conductance G with a voltage V and the current I = G·V is already the product — one multiplication, one device, no logic.
KIRCHHOFF
The column sums
Tie 256 cells to one wire and the currents add themselves. A 256×256 tile is 65,536 multiply-accumulates in a single physical event.
GEOMETRY
The state is atoms
A weight is the shape of a conductive filament a few nanometers wide — not stored charge. A particle strike has nothing to flip.
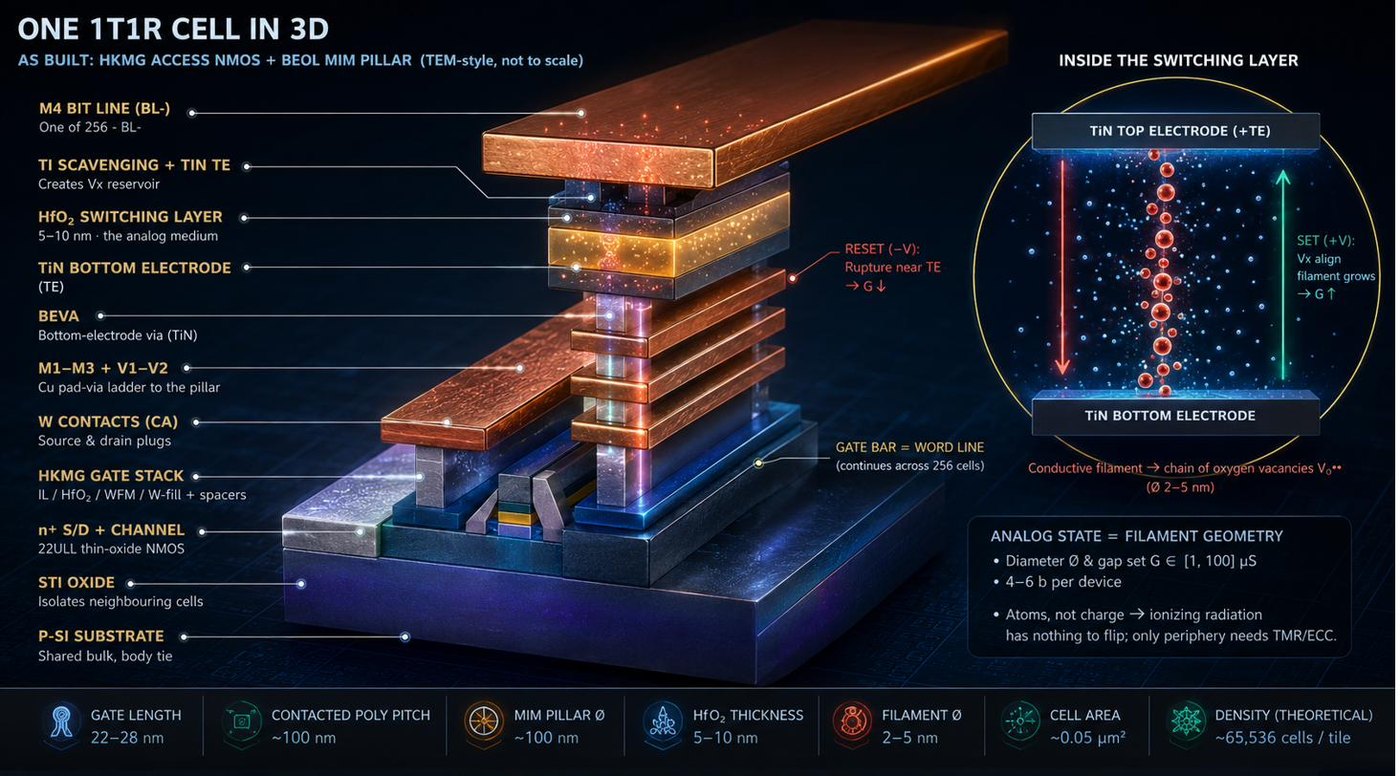
One 1T1R cell, as built — the conductive filament inside the HfO₂ is the weight